1 ACID
Transaction (tx)
- Collection of db queries
- Transaction Lifecycle : Begin , Commit / Rollback , End
Atomicity
- All queries in a transaction must succeed.
- If one query fails, all prior successful queries in transaction should rollback.
- If db goes down, all successful queries should be rolled back.
Isolation
- Can one tx see changes made by other txs ?
- Read Phenomena
- Isolation levels
Isolation - Read Phenomena
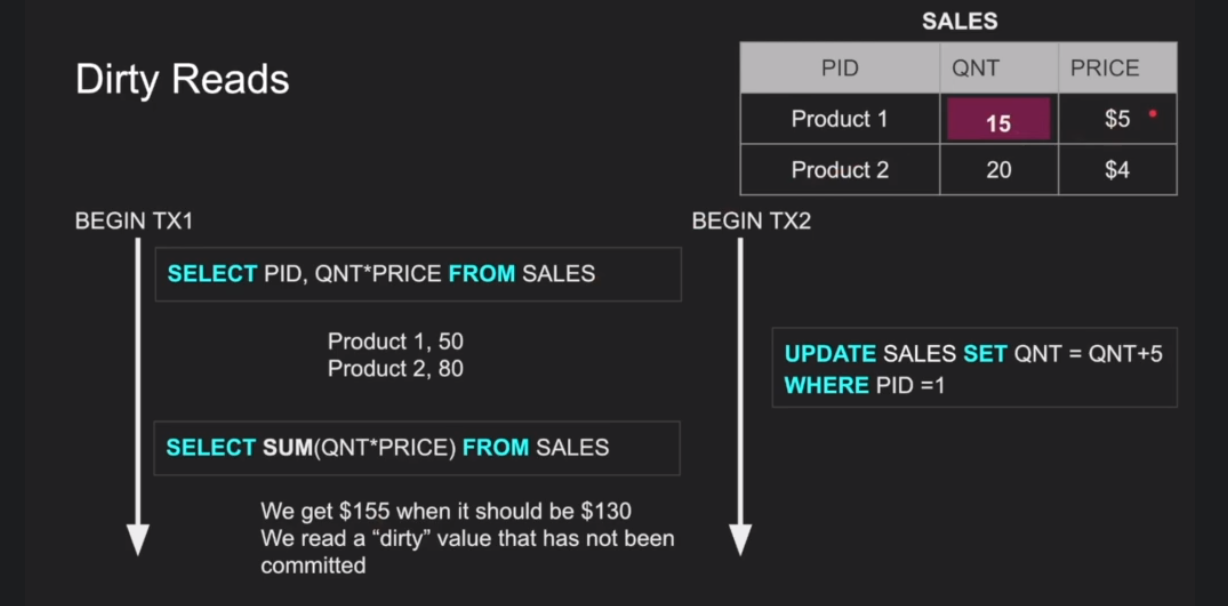
Dirty Reads : One tx reading uncommited change of another tx. Reads inconsistent values within a tx.
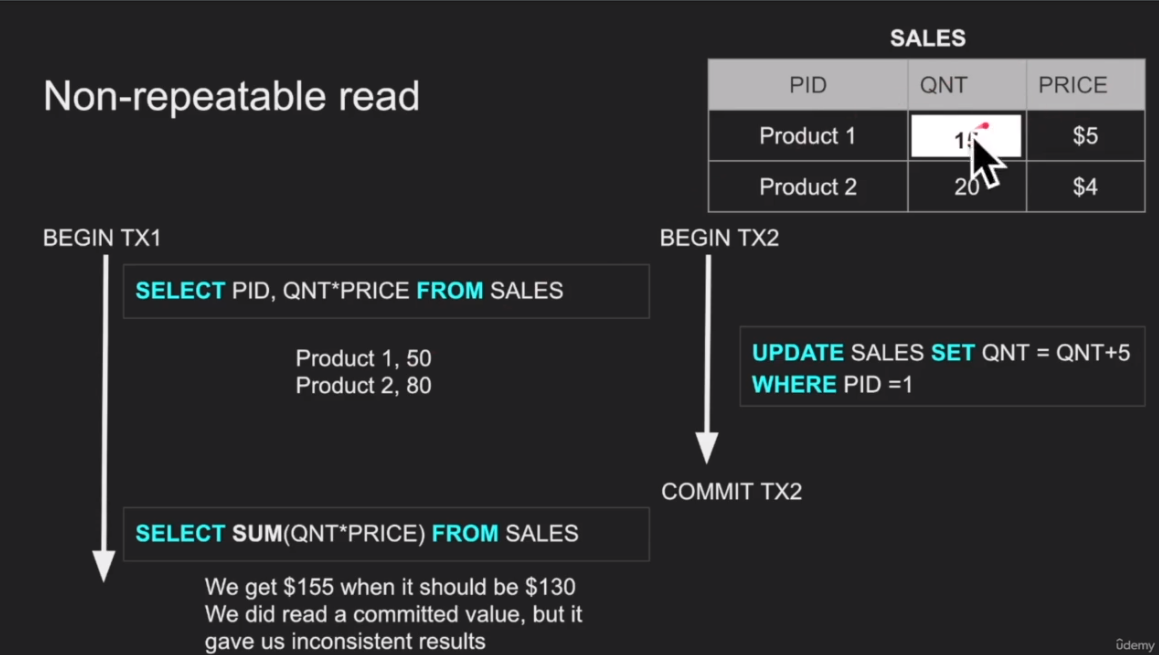
Non-Repeatable Reads : First do select * and then doing select sum(*) reads the same value again but values are changed. Including changes from other committed txs.
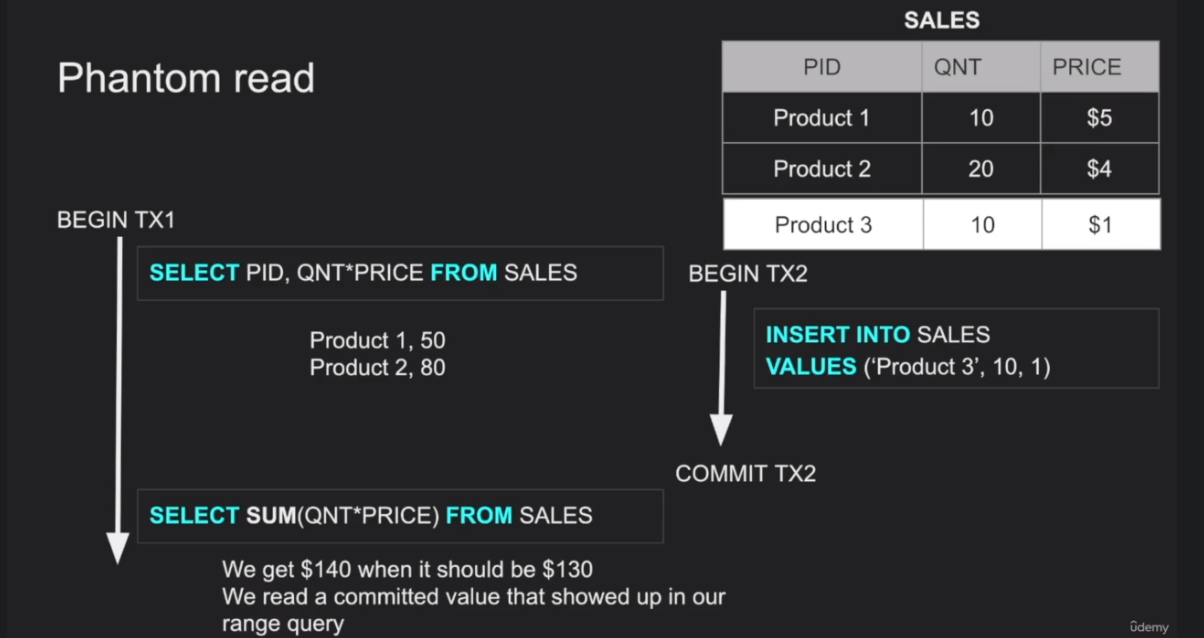
Phantom Reads : First some rows are read with a query (for ex: range query) and then new rows were added and upon running the same query again, some newly added rows are present in the result which were not present before.
Lost Updates : For 2 txs T1 , T2. T1 updates some rows, T2 updates conflicting rows, then T1 reads to get inconsistent result.

Basically all these cases are some kindof inconsistency within a transacation where a later query is affected by other txs resulting in a different result.
Isolation Levels for Inflight transactions
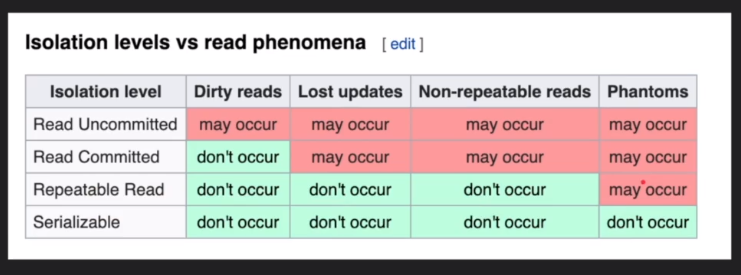
Read Uncommitted : No isolation (lowest). Any tx can read any other tx's uncommitted / committed change.
Read Committed : Each query only sees committed changes made by other txs. Default isolation level for many dbs.
Repetable Read : tx will lock the needed rows (read rows) while its running so that other txs cant update it.
Snapshot : Each query only sees changes that has been commited before the start of tx.
Serializable : Txs run as if they are serialized.
Special Case of Postgres : in Repeatable read isolation level, phantom reads are blocked automatically
Database implementation of Isolation
- Pessimistic : Row level locks, table locks, page locks.
- Optimistic : No locks, just fail txs if things are changed by other tx inbetween.
Consistency
- Consistency in data
- Consistency in reads
Consistency in Data
Occurs when we have multiple views or representation of data ( Ex: foreign key constraint, multiple tables ).
Factors ensuring consistency in data
- Enforcing referential integrity (foriegn keys). Preventing inconsistency of same data in diff tables (think of likes and no of likes example).
- Atomicity
- Isolation
Consistency in Reads
- If a tx TX1 committed a change, will new tx see the change immediately ?
- In Db clusters like InnoDB cluster where there is a master and 3 slaves, which enforces eventual consitency, we might sometimes get old values before the data is eventually consistent.
Durability
- Persisting writes to db to non-volatile storage systems like disks.
- Changes made by committed txs should be persisted in a durable non-volatile storage
Durability Techniques
- WAL(Write ahead log) : All changes are immediately flushed to disk
- Asynchronous snapshot
- Append only file
WAL (Write Ahead Log):
- Writing a lot of data to disk is expensive
- Conventional DBMSs use compressed version of changes called WAL Segments.
OS Cache:
- A write request in OS usually goes to OS Cache for performance reasons.
- This is a problem, because when OS crashes, all data in cache is lost and db data is not persisted.
- Fsync OS command forces writes to always go to disk.
Repeatable Reads vs Serializable Reads
Consider the following example, where tx1 changes all a's to b's and tx2 changes all b's to a's.

In read-committed / repeatable-read isolation level, only the particular row needed by the transaction are locked. As both txs has uncommon rows, isolation level wont prevent them from updating.
In serializable isolation level, transactions are executed as though they are executed serially.

Try this example, its beautiful !!!
Consistency and Eventual Consistency
2 types
Eventual Consistency in Reads
==Orange== node is master node and ==Green== nodes are slave nodes.
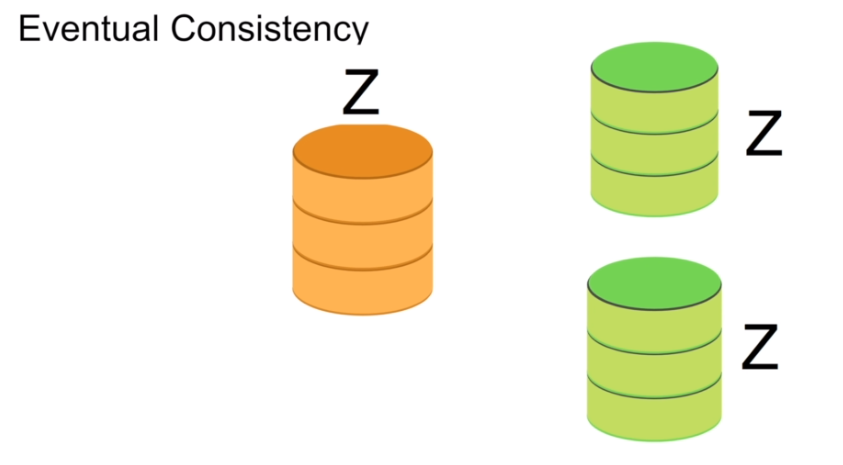
Write updates are given to master node.
Reads take place on any of the 3 depending upon the loads.
Eventually master node shares the write updates to slave nodes. Until then, data remains inconsistent and read values are not the latest one.